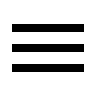

코로나19 바이러스의 장기화로 비대면이 일상화 되면서, 4차 산업혁명으로 기술 발전이 앞당겨짐에 따라서 국내외 시장 환경이 디지털 중심으로 빠르게 변화하고 있습니다.
그런데 이 같은 환경 속에서도 촉망받고 있는 일거리가 있다고 하는데요.
오늘은 직장인을 비롯해서 주부, 학생, 중장년층, 노인층까지 스마트폰이나 PC 등 전자기기만 있으면 가능한 4차 산업혁명 알바를 소개해드릴까 합니다.

데이터 라벨링
데이터 라벨링이란? 말 그대로 데이터에 이름표를 붙이는 작업입니다. 개발하려는 인공지능 소프트웨어에 따라 필요한 Data가 다릅니다.
그런데 일정 수준의 학습을 받은 사람은 사물이나 이름을 분류할 수 있지만, 인공지능은 그렇지 않습니다.
여기서 인공지능(AI) 학습을 위해 사람이 직접 Data를 분류하고 가공하는 모든 작업을 바로 '데이터 라벨링'이라고 합니다. 그만큼 정교한 작업이 필요하기 때문에 아직까지는 사람의 힘이 필요한 것이죠.

데이터 라벨링은 한 건당 20원~3,000원 정도로 건당 수익이 크지는 않지만, 한 번에 수십 개에서 수백 건을 할 수 있을 정도의 간단한 재택 알바 업무입니다.
그래서 누구나 쉽게 접근할 수 있는 것이 주요 메리트라고 할 수 있습니다.
데이터 레벨링은 크게 4가지 유형별 프로젝트로 구분되며, 작업 방식은 2가지로 구분되는데요. 먼저 첫 번째 이미지 프로젝트부터 소개해드리도록 하겠습니다.

첫 번째. 이미지 프로젝트
1) 수집
휴대폰으로 정해진 대상을 촬영해 업로드하는 작업입니다. 온라인에서 이미지를 다운로드하여 업로드하게 되면 저작권 문제가 발생하기 때문에 작업 화면에서 바로 카메라로 찍고 업로드 하는 형태입니다.
이는 사진 수집 뿐만 아니라 동영상, 음성도 모두 동일합니다.
2) 가공
바운딩 : 이미지에서 정해진 대상을 마우스로 드래그하여 박스를 그리는 작업입니다. 정교하게 박스를 그리는 것이 중요하기 때문에 스마트폰이 아닌, PC에서만 참여가 가능합니다.
박스를 그린 후에는 해당 대상이 무엇인지 분류하는 '태깅', 바운딩 대상이 글자인 경우 해당 글자를 입력하는 '전사'로 이어집니다.
(이러한 유형의 결과물들은 향후 자율 주행 개발 등 광범위한 인공지능 개발에 활용됩니다)
스켈레톤 추출 : 대상의 특정 부위에 점을 찍는 작업입니다.
(가공된 결과물은 이미지나 영상의 객체를 인식하는 소프트웨어를 개발하는 데 활용됩니다.)
OCR : OCR은 인공 지능에 글자를 가르쳐주기 위한 프로젝트입니다.
화면에 있는 이미지 내 글자를 바운딩해 해당 텍스트의 가로, 세로 여부를 선택하거나 글자를 입력하는 프로젝트로 다른 프로젝트에 비해 난이도가 다소 높은 편에 속합니다.
또한 글자 바운딩 기준은 고객사의 요청에 따라 결정되기 때문에 작업 기준을 꼭 가이드에서 자세히 확인해야 합니다.
감정 태깅, 상태 묘사 : 사진 속 사람의 표정을 보고 감정을 추론해 태깅하거나 이미지를 글로 상세히 묘사하는 작업입니다.

두 번째. 영상 프로젝트
1) 수집
영상 수집은 휴대폰으로 정해진 대상이나 행동을 촬영해 업로드하는 작업입니다. 온라인에서 영상을 다운로드해 업로드할 경우 저작권 문제가 발생하기 때문에 작업 화면에서 바로 카메라를 실행해 촬영해 업로드하는 형태로 진행됩니다.
2) 가공
구간 추출 : 영상에서 특정 구간을 선택하는 작업입니다. 예를 들어 화자가 특정 동작이나 대사를 말할 때 해당 구간을 선택하는 등 고객사에서 필요한 Data에 따라 영상의 구간을 선택해 추출합니다. 구간 추출 후 감정을 태깅하거나 대사를 받아쓰는 작업으로 이어지기도 합니다.
바운딩 : 이미지 작업과 동일하게 영상에서도 정해진 대상을 마우르로 드래그해 바운딩하는 작업입니다. 바운딩 후 대상을 분류하는 태깅으로 이어질 때가 많습니다.
스켈레톤 추출 : 이미지 작업의 방식과 동일하게 영상에서도 이미지와 동일하게 대상의 특정 부위에 점을 찍는 작업이 진행됩니다.
세 번째. 텍스트 프로젝트
1) 수집
주어진 시나리오에 맞는 Q&A 대화를 만들거나 제시된 지문을 읽고 질문을 만드는 작업입니다. 이렇게 수집된 결과물은 챗봇이나 기계 독해 엔진을 만들 때 사용됩니다.
2)가공
문장 비교 : 주어진 문장을 읽고 의미가 같은지, 다른지 태깅하는 작업입니다. 가공된 결과물은 인공 지능의 문장 파악 정확도를 항상하는 데 활용됩니다.
감정 태깅 : 주어진 문장을 읽고 느껴지는 감정을 태깅하는 작업으로 인공지능의 감정 인식을 고도화하는 데 활용됩니다.
키워드 찾기 : 대화 속 주제의 키워드를 찾는 작업으로 챗봇을 고도화하는 데 활용됩니다.
문장 요약 : 지문을 읽고 핵심 내용을 요약하는 작업으로 인공 지능이 정보성 글의 핵심 내용을 인식하는 알고리즘을 개발하는 데 활용됩니다.
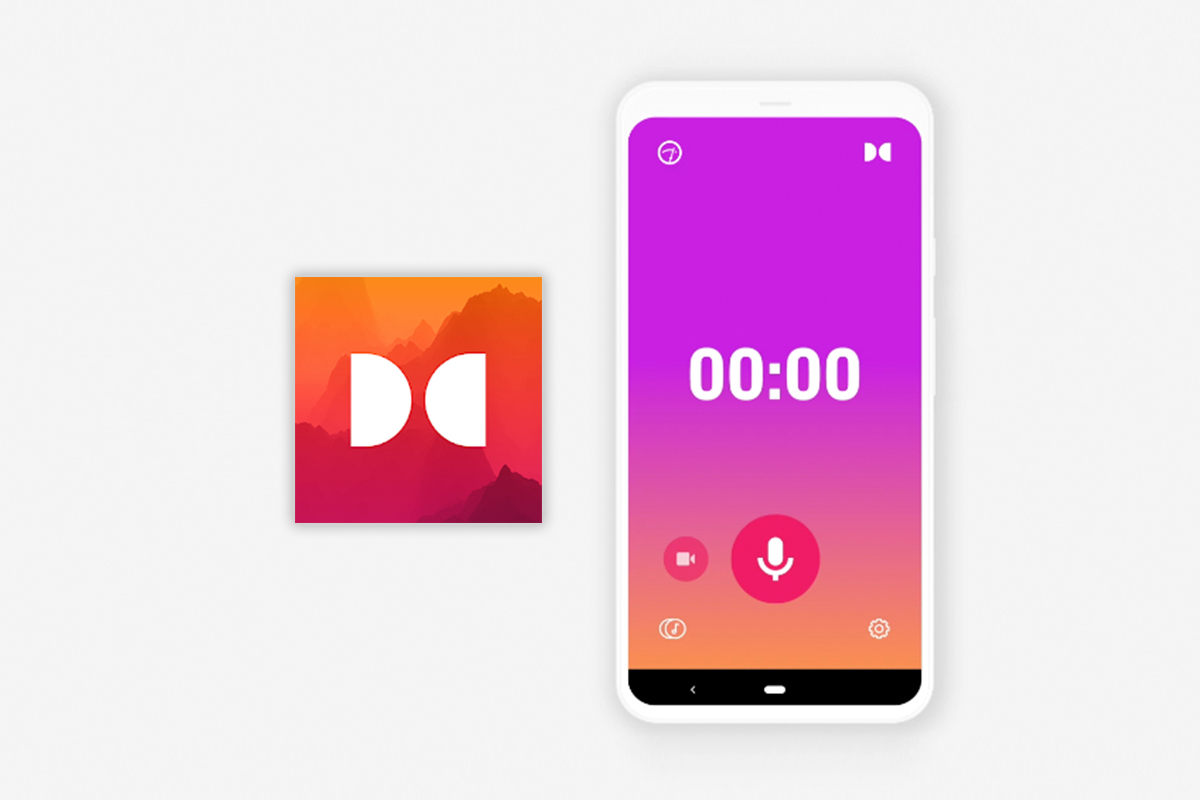
네 번째. 음성 프로젝트
1) 수집
휴대폰으로 정해진 문장을 녹음하는 작업 : 이미지나 동영상과 동일하게 온라인에서 다운로드해 업로드할 경우 저작권 문제가 발생하기 때문에 작업 화면에서 제공되는 녹음 기능을 이용해 녹음하고 제출하는 형태로 진행됩니다. 작업 시 조용한 곳에서 녹음을 진행하여 제출해야 합니다.
녹음 작업의 검수 기준은 고객사에서 요구한 조건대로 결정되기 때문에 프로젝트 별로 검수 기준에 다소 차이가 있을 수 있습니다.
2) 가공
음성 받아쓰기 : 주어진 음성을 듣고 들리는 대로 받아쓰는 작업으로 자막 자동 생성이나 대본 자동 작성 프로그램을 개발하는 데 활용됩니다. 기준 음성과 비교 대상 음성을 듣고 화자가 같은지, 다른지를 태깅하는 작업입니다.
(인공지능 스피커를 고도화하는 데에 활용됩니다.)

데이터 라벨링 개념은 여기까지 인데요. 어느 정도 익히셨나요? 어느 정도 익히셨으면 아래 사이트를 통해 활동하실 수 있습니다.
※ 단, 위 내용은 '크라우드 웍스' 학습 내용을 정리한 것으로, 사이트마다 운영방식의 다소 차이가 있을 수 있습니다.



